C++ & Trading Systems Interview
Overnight cramming has helped no one. This is NOT a last minute tutorial for LeetCode style problems. Go to references section for further exploration.
Use thy precious’s cpplayout and change -std=c++17 to your fav C++ spice and ensure you’re on Linux. Or just admit OnlineGDB is better for the job.
1. Keep me in your memory
Question: Why is it advisable to use std::string_view (C++17) over reference to std::string?
A std::string is 32 bytes long as it has to maintain capacity to store potential addition of characters
struct string_impl {
char* ptr; // pointer to character buffer
size_t size; // current length (not including '\0')
size_t capacity; // allocated capacity
};
which string_view does not need hence is smaller (16 bytes).
struct string_view {
const char* ptr; // pointer to character buffer (non-owning)
size_t size; // length of the viewed string
// Note: no capacity, as string_view does not own memory
};
Let’s see with an example
#include <iostream>
#include <string_view>
void printAddr(std::string_view sv)
{
std::cout << (void *)sv.data() <<"\n";
}
int main()
{
std::string s {"How Long"};
auto ptr = s.c_str();
std::cout << (void *)ptr << "\n";
printAddr(s);
s += "too ";
ptr = s.c_str();
std::cout << (void *)ptr << "\n";
printAddr(s);
s += "loooooooooooooooooooooooooooooooooooong";
ptr = s.c_str();
std::cout << (void *)ptr << "\n";
printAddr(s);
return 0;
}
0x7ffce0e132f0 | Underlying pointer of string object creates memory
0x7ffce0e132f0 | String view looks at the same memory
0x7ffce0e132f0 | A few Additional characters didn't exceed capacity
0x7ffce0e132f0 |
0x622dbdb1e6c0 | But a shit ton did. New memory space was required to accomodate them
0x622dbdb1e6c0 | String view is looking at the same memory location
Size of pointers depend on architecture of the machine. Its always the word size, i.e., 8 bytes for 64 bit machines.
#include <iostream>
int main()
{
char ch;
char ptr[3];
char *cpy = ptr;
std::cout << sizeof(ch) << ", " << sizeof(ptr) << ", " << sizeof(ptr+0) <<", "<< sizeof(cpy) << std::endl;
return 0;
}
C++ is going to see ptr as an array object of size 3 while (ptr+0) as a character pointer. Therefore both (ptr+0) and cpy yields 8 bytes.
Its impossible for a class to have an object with size = 0 as that would imply multiple objects existing at the same address.
#include <iostream>
class WithCharMember { char _placeholder; };
class WithIntMember { int _placeholder; };
class WithNoMember {};
int main()
{
WithCharMember charArray[10];
WithIntMember intArray[10];
WithNoMember noArray[10];
std::cout << sizeof(WithCharMember) << "*10 = " << sizeof(charArray) << std::endl;
std::cout << sizeof(WithIntMember) << "*10 = " << sizeof(intArray) << std::endl;
std::cout << sizeof(WithNoMember) << "*10 = " << sizeof(noArray) << std::endl;
return 0;
}
1*10 = 10
4*10 = 40
1*10 = 10
Having a virtual pointer in the class in case we’re inheriting from a base class or have at least one virtual method declared would make the class size equal to the system’s word size (8 for 64 bit). Assume we’re on a 64 bit system for the remainder of this article.
#include <iostream>
class A { virtual int func()
{ return -1; }};
class B : public A {};
class C {};
int main()
{
std::cout << "sizeof(A)=" << sizeof(A) << ", ";
std::cout << "sizeof(B)=" << sizeof(B) << ", ";
std::cout << "sizeof(C)=" << sizeof(C) << std::endl;
return 0;
}
sizeof(A)=8, sizeof(B)=8, sizeof(C)=1I am sure that makes you wonder how is memory even laid out. I can attempt to explain but can’t make it any simpler than this youtube video. Subscribe to Rupesh’s channel[1] please.
Question: What’d be the size of class B if it also had
- int e;
- int e,f;
- int e; double d; char x;
1. 16
|v|v|v|v|v|v|v|v| (from class A)
|e|e|e|e|-|-|-|-|
First 8 bytes are for vptr
The next 4 are occupied by integer e
Remaining 4 are empty
2. 16
|v|v|v|v|v|v|v|v| (from class A)
|e|e|e|e|f|f|f|f|
First 8 bytes are for vptr
The next 4 are occupied by integer e
And remaining 4 by integer f
3. 32
|v|v|v|v|v|v|v|v| (from class A)
|e|e|e|e|-|-|-|-|
|d|d|d|d|d|d|d|d|
|x|-|-|-|-|-|-|-|
First 8 bytes are for vptr
The next 8 are occupied by double data member
And yes, only one byte is occupied by character x
Just like a group trip, not everyone contributes equally (to class size). For example, when we have to use a bitfield. Consider a structure (MessageHeaderOut) that BSE’s Enhanced Trading Interface API uses.
| Field Name | Len | Offset | Data Type |
|---|---|---|---|
| BodyLen | 4 | 0 | unsigned int |
| TemplateID | 2 | 4 | unsigned int |
| Pad2 | 2 | 6 | Fixed String |
How are we supposed to make a structure which has 2 bytes of unsigned int? Of course one valid answer would be to
#include <cinttypes>
struct MessageHeaderOut {
uint32_t BodyLen;
uint16_t TemplateID;
char Pad2[2];
};
But we are nerdy people. We’ll use just the first 2 bytes of an unsigned integer
struct MessageHeaderOut {
unsigned int BodyLen;
unsigned int TemplateID: 16; // 2 bytes of unsigned int
char Pad2[2];
};
Static data members do NOT contribute to the size of a class.
#include <iostream>
class A {
char placeholder;
public:
static int x;
};
int A::x;
template<typename T>
class B {
char placeholder;
public:
static int x;
};
template<typename T>
int B<T>::x;
int main()
{
A A_1, A_2;
B<int> B_int_1, B_int_2;
B<char> B_char_1, B_char_2;
A_1.x = 123;
B_int_1.x = 234;
B_char_1.x = 345;
std::cout << "A_1's x = " << A_1.x <<", A_2's x = " << A_2.x << std::endl;
std::cout << "B_int_1's x = " << B_int_1.x <<", B_int_2's x = " << B_int_2.x << std::endl;
std::cout << "B_char_1's x = " << B_char_1.x << ", B_char_2's x = " << B_char_2.x << std::endl;
return 0;
}
A_1's x = 123, A_2's x = 123
B_int_1's x = 234, B_int_2's x = 234
B_char_1's x = 345, B_char_2's x = 345
All objects of A have the same x. All objects of B
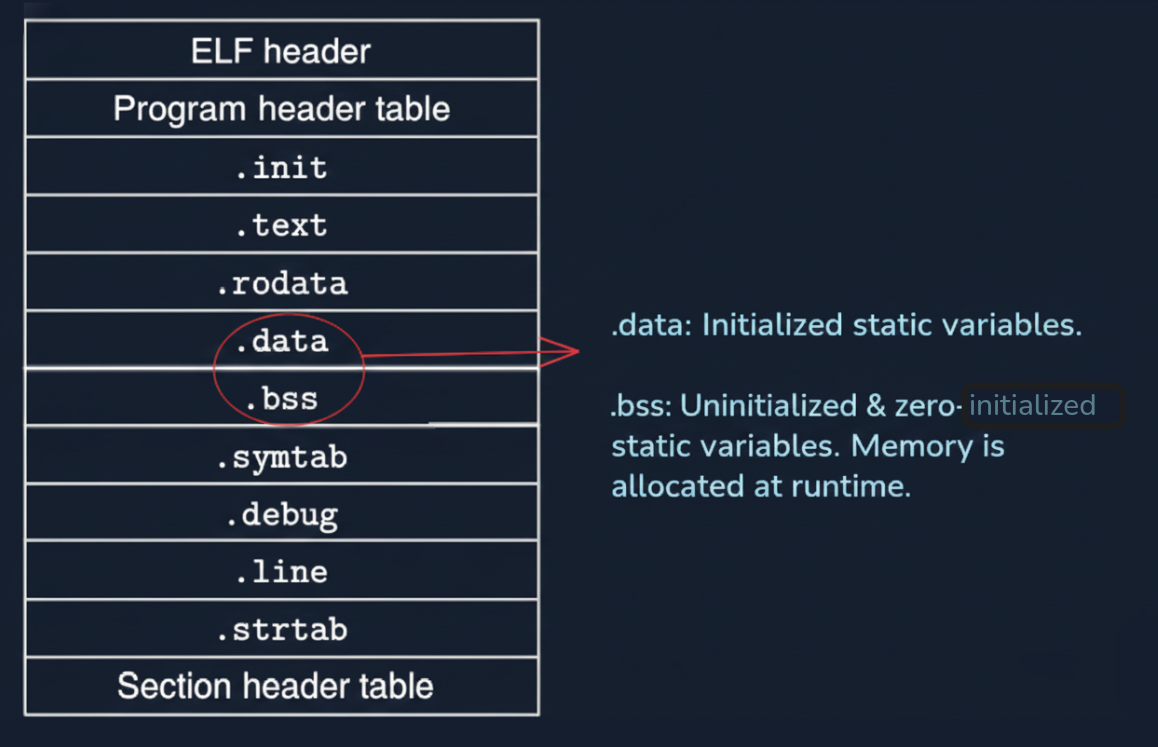
Image courtesy of Department of Computer Science, Columbia University.
objdump -t -C /path/to/bin | grep .bss
# Change int A::x = 99; to send A::x to .data section

Thy precious suggests we read chapter 7 of Computer Systems book[2] for much deeper understanding.
Let’s go back to something more simple. Inhertiance. Riddle thy precious this - how does accessibility change when a different visibility modifier.
| Private | Protected | Public | |
|---|---|---|---|
| Private | X | Private | Private |
| Protected | X | Protected | Protected |
| Public | X | Protected | Public |
And while we are at it, what’s the difference between having a protected member and a private member anyway?
Just like an interview setting thy precious shall answer the easier question first.
#include <iostream>
class Base {
private:
int notAccessible {-1};
protected:
int derivedMethodAccessible {0};
public:
int fullyAccessible {1};
};
class Derived : public Base {
public:
Derived() = default;
void ConfirmAccessibility()
{
std::cout << "Base's protected member value: " << derivedMethodAccessible << std::endl;
}
};
int main()
{
Derived d;
d.ConfirmAccessibility();
// d.derivedMethodAccessible; ERROR
return 0;
}
Private members are accessible by ONLY members of the same class. We will get to having “friends” later. This implies that we can’t just declare an object of base class and try accessing its private parts.
int main()
{
Base b;
// b.notAccessible; ERROR Just Like Protected
return 0;
}
We should checkout the memory layout of these Derived class objects.
class Base {
private:
int _basePrivate;
protected:
int _baseProtected;
public:
int _basePublic;
};
class Derived : public Base {
int _derivedPrivate;
public:
int _derivedPublic;
};
Base object is laid out as
|B|B|B|B|
|B|B|B|B|
|B|B|B|B|
Derived object constructs the base subobject before derived
|B|B|B|B| Now let's play with *visibility modifier*
|B|B|B|B| And see how access to these base members get
|B|B|B|B| Affected by flipping between public, protected and private
|D|D|D|D|Refer to the table here. X implies that the member will not be accessible anymore.
class Derived : private Base {
|B|B|B|B| RIP _basePrivate - memory stays
|B|B|B|B| _baseProtected is to be treated as a private member of Derived
|B|B|B|B| _basePublic is to be treated as a private member of Derived
|D|D|D|D|
class Derived : protected Base {
|B|B|B|B| RIP _basePrivate - memory stays
|B|B|B|B| _baseProtected is to be treated as a protected member of Derived
|B|B|B|B| _basePublic is to be treated as a protected member of Derived
|D|D|D|D|
class Derived : public Base {
|B|B|B|B| RIP _basePrivate - memory stays
|B|B|B|B| _baseProtected is to be treated as a protected member of Derived
|B|B|B|B| _basePublic is to be treated as a public member of Derived
|D|D|D|D|
We can notice that C++ doesn’t change the frame in which memory is laid out despite some members not being accessible down the line. Pay homage to those who came before us. Amen. “Object integrity is upheld in C++” in case the interviewer doesn’t like our jokes. Keep applying at other firms life is too short to put up with annoying people.
Friendships can be tricky. You being friend to one doesn’t imply he/she will reciprocate.
#include <iostream>
class Yash {
int secret;
public:
Yash(int _init=69): secret(_init) {}
friend class Vaibhav;
};
class Vaibhav
{
int secret;
public:
Vaibhav(int _init=80085): secret(_init){}
static int Display(Yash& obj)
{ return obj.secret; }
};
int main()
{
Yash y;
std::cout << "Value of Yash's private member via a (fake) friend: " << Vaibhav::Display(y) << std::endl;
return 0;
}
Vaibhav has access to Yash’s private info because he is a friend according to Yash. But Yash knows no secret that Vaibhav keeps from him. Careful who you call a friend. Not everyone who smiles at you is one. Only Yash can decide who should be his friend. For the sake of poetic justice let’s see how a true friend should have behaved.
static int Display(Yash& obj);
};
int Vaibhav::Display(Yash& obj) {
std::cout << "A brother doesn't snitch, officer.";
return -1;
}
| Creation | Annhilation |
|---|---|
| new | delete |
| new[] | delete[] |
| malloc() | free() |
| calloc() | free() |
Question: How did delete ptr find out it needs to delete exactly 40 bytes when it only had pointer location as its parameter (NOT size)
It’s simple actually. The allocator stores metadata for book keeping. Depending on the implementation it can be stored right before the user-space or in some other look up table. This is why we ought to use the right deallocator as mentioned in the above table.
#include <iostream>
int main()
{
int *ptrNew = new int(10);
int *ptrMalloc = static_cast<int*>(malloc(sizeof(int)*10));
int ptrStack[10];
free(ptrMalloc); // free has the metadata from malloc
free(ptrNew); // free does NOT have ptrNew's metadata
//delete ptrNew; // has ptrNew's metadata. Use this instead.
return 0;
}
Using wrong deallocator is an undefined behaviour and “mismatched allocation function” warning must have been thrown at compile time itself. There might be a case of memory leak or a crash.
Book keeping data with address of first element implies that if you pass in an address that’s not int the table results in UB. Your program might also crash.
#include <iostream>
int main()
{
int *ptrNew = new int(10);
ptrNew++;
free(ptrNew); // Undefined Behaviour.
return 0;
}
Question: If malloc and new both allocate memory in heap, how are they different from each other?
Good question. Lets look at the output of the following code.
#include <iostream>
class Widget {
int data;
public:
Widget(): data(100) { std::cout << "Constructor of Widget was called" << std::endl;}
int GetData() { return data; }
};
int main()
{
Widget *mallocPointer = static_cast<Widget*>(malloc(sizeof(Widget)));
Widget *newPointer = new Widget;
std::cout << "newPointer->GetData(): " << newPointer->GetData() << std::endl;
std::cout << "mallocPointer->GetData(): " << mallocPointer->GetData() << std::endl; // UB - data members were not initialized
return 0;
}
A constructor is called only when “new” is used. Use “placement new” to invoke constructor implicitly when allocating space with malloc.
#include <iostream>
// #include <new> // For placement new, other standard headers will be including this anyway
class Widget {
int data;
public:
Widget(): data(100) { std::cout << "Constructor of Widget was called" << std::endl;}
int GetData() { return data; }
};
int main()
{
Widget* ptr = static_cast<Widget*>(malloc(sizeof(Widget)));
if (ptr) new(ptr) Widget();
std::cout << ptr->GetData() <<"\n";
return 0;
}
2. Virtual Reality
Question: Why are virtual functions slow?
Hold your 🐎🐎🐎. There are three kinds of cache - instruction, data and unified (that handles both instruction and data).

Thy precious isn't known for his penmanship. Above figure demonstrates what has been said below..
Base class has a virtual pointer that points to the virtual table. It may not be in cache that causes (1) Data Cache Miss. After having loaded this table in memory we need to get the function pointer which again may not be in cache resulting in (2) Data Cache Miss. Finally, the function instructions are executed after a potential (3) Instruction Cache Miss. Non virtual functions will only have to encounter (3).
In HFT we avoid this runtime overhead by using Curiously Recurring Template Pattern (CRTP). Let’s look at an example with virtual method and go about refactoring it.
#include <iostream>
class Base {
public:
virtual int GetID() { return -1; }
};
class Derived : public Base {
int _id;
public:
Derived(int init=1): _id(init) {}
int GetID() { return _id; }
};
int main()
{
Derived d;
Base& b= d;
std::cout << b.GetID() << std::endl;
return 0;
}
The runtime overhead of virtual method calling will be too much of a burden. Let’s get rid of this the CRTP way.
#include <iostream>
template<typename Derived>
class Base {
Derived& GetDerived() { return static_cast<Derived&>(*this); }
public:
int GetID() { return GetDerived().GetID(); }
};
class Derived : public Base<Derived> {
int _id;
public:
Derived(int init=1): _id(init) {}
int GetID() { return _id; }
};
int main()
{
Base<Derived> b;
std::cout << b.GetID() << std::endl;
return 0;
}
That was an easy speed up now, wasn’t it?
3. Atomic Weapons[4]
For someone who has time in hand, thy precious recommends “C++ Atomic Operations and Memory Ordering” playlist by CppHive[3].
There are 6 memory ordering options.
std::memory_order_seq_cst (default) - Sequential Consistent
std::memory_order_relaxed
std::memory_order_aquire
std::memory_order_release
std::memory_order_acq_rel
std::memory_order_consume
With sequential consistent, every thread will see the atomic value after the same N number of operations performed on it. Its the safest option which naturally makes it default but slow. Compiler demands overhead in terms of additional store buffer flushes and cache refreshes. Also there can be no instruction reordering optimizations.

We can specify 2 (success/failure) memory ordering for compare and exchange case.

std::memory_order_relaxed, we should be able to get rid of overhead mentioned with sequential consistent by not caring about synchronization. But do keep in mind that when all we have is a hammer then everything will look like a nail. There are good reasons for having other memory order. Sometimes we crave for limited synchronization.
So far we've understood
Write Memory Order -> Read Memory Order
---------------------------------------
(1) std::memory_order_seq_cst -> std::memory_order_seq_cst (We care A LOT about sync among threads)
(2) std::memory_order_relaxed -> std::memory_order_relaxed (We don't care about threads being in sync at all)
 (3) std::memory_order_release -> std::memory_order_acquire (When we want sync among few variables declared)
(4) std::memory_order_release -> std::memory_order_consume Special case of acquire: Only dependent variables are in sync
(3) std::memory_order_release -> std::memory_order_acquire (When we want sync among few variables declared)
(4) std::memory_order_release -> std::memory_order_consume Special case of acquire: Only dependent variables are in sync4. Spin Lock
Give thy precious some more time to type things out
5. Smart Pointers
Give thy precious some more time to type things out
References
1. CppNuts (YouTube Channel)
2. Computer Systems by Bryant and O’Hallaron
3. CppHive (YouTube Channel)
4. Herb Sutter - Atomic Weapons (YouTube Video).